Considero que hoje em dia as mais poderosas ferramentas abertas, que podem nos auxiliar efetivamente a garantir conformidade com a LGPD, são o padrão RDF da Web Semântica, as linguagens SparQL e SQL, e a Wikidata. Estão todas imersas num ecossistema bastante estável e totalmente interoperável. Vejamos como…
Como a Wikidata pode ajudar a descobrir quais dados da minha empresa são dados sensíveis no âmbito da LGPD!?
Receita através de exemplos
O algoritmo a seguir pode ser automatizado, não se assuste, a intensão aqui é demonstrar a aplicabilidade e relevância das ferramentas.
Primeiro passo. Experimente essa consulta SparQL na Wikidata. Basta seguir o link e clicar no play.
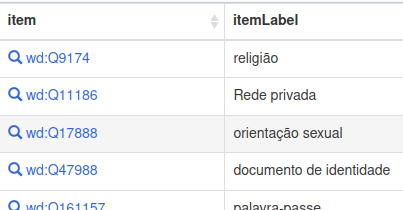
No resultado você vai encontrar todos os conceitos, elencados e não-elencados explicitamente na LGPD. Podemos portanto apelidar essa lista de “itens LGPD”. Eles foram atribuídos por suas relações semânticas, e são consistentes com todo universo de conceitos geridos e bem definidos pela Wikipedia. Ou seja, agregam conhecimento universal auditado por uma comunidade de milhares de experts e usuários.
Por exemplo o conceito de “orientação religiosa da pessoa” é definido univocamente como conceito Q9174, e como uma subclasse de sistema de crenças (Q5390013) e ideologia (Q7257)… Ou o conceito bem mais objetivo de número de telefone (Q214995), uma subclasse de identificador (Q853614) e de endereço de rede (Q4418000).
Como isso foi possível? Simples, todos os ~20 conceitos listados são subclasse também do elemento-chave da LGPD, o conceito de dados pessoais (Q3702971). A consulta SparQL seleciona todos os itens da “enciclopédia RDF Wikidata” que satisfazem a frase:
Item é subclasse (P279) de dado pessoal (Q3702971).
Segundo passo. Vamos então organizar esses resultados em dois grupos, “Caracterização da pessoa natural” e “Potencial informação sensível”. Como vimos na discussão acima, a LGPD só considera sensíveis os dados pessoais quando vinculados à pessoa natural.
Precisamos identificar esses dois grupos para, só então depois, conferir se eles ocorrem vinculados na base de dados da empresa.
Nota: a listagem acima não é completa, se alguém se animar criamos uma em planilha.
Exceto pelo grupo “legalmente sigiloso” das potenciais informações pessoais, sem a vinculação com a pessoa, todos os demais itens isolados podem ser públicos. Por exemplo uma listagem de “datas de nascimento mais frequentes no Brasil” é um dado público.
Terceiro passo. É o momento mais técnico e suado da nossa receita, incluir descritores semânticos no banco de dados da empresa.
Bancos de dados típicos (SQL) são conjuntos de tabelas, análogas planilhas CSV ou Excel, onde cada coluna tem um nome, conhecido como “nome do campo” ou “nome da coluna”. De agora em diante a sua empresa vai precisar catalogar esses nomes de coluna da seguinte forma:
-
Escolher vocabulários complementares à Wikidata (prefixo wd), e seus prefixos. O mais popular entre os arquitetos de bancos de dados é o Schema.org (prefixo sh), mas podem ser qualquer outro da preferência da empresa ou sua especialidade.
-
A cada tabela determinar as classes semânticas que se aplicam a ela. Por exemplo a tabela Clientes que lista nome, telefone e CNPJ de clientes pode ser classificadas como ambos sh:Organization e wd:Customer. Já a tabela Colaboradores que lista os nome, CPF e data de nascimento dos funcionários seria classificada como sh:Person e wd:Employ.
-
A cada coluna deterninar aproximadamente o seu significado: por exemplo nome, tanto de pessoa como de organização, é a propriedade sh:name. Já o números de CPF e de CNPJ podem ser associados precisamente com o vocabulário Wikidata, ou aproximadamente com o seu genérico no vocabulário SchemaOrg, o sh:vatID.
Nota técnica 1: a Wikidata comporta uma infinidade de outros vocabulários através da declaração de equivalência semântica.
Por exemplo nesta parte da Wikidata declara-se a equivalência wd:Person ≅ sh:Person.
Quando essa equivalência é reconhecida de ambas as partes, dizemos que há uma “ponte semântica” sólida entre os vocabulários. Por exemplo a ponte SchemaOrg-Wikidata ou OpenStreetMap-Wikidata.
Nota técnica 2: para efeitos de discussão aqui como tag semântica não precisamos, mas existe a sutileza de se diferenciar propriedade de classe. Por ex. na Wikidata a classe wd:Telephone = wd:Q214995 designa o aparelho, enquanto a propriedade wd:telephone = wd:P1329 designa um valor de número de telefone.
Na Wikidata as propriedades são apenas para a gestão interna do banco e dados, possuindo sempre seus equivalentes conceituais. Por ex. a classe wd:PersonName (Q1071027) e a propriedade wd:personName (P1559).
Quarto passo. Enfim, agora que o trabalho duro foi realizado, resta conferir na seguinte sequência:
-
A cada tabela, conferir se sua semântica bate com um dos itens LGPD (listagem do primeiro passo). Se for “caracterização da pessoa natural” já pode ser eleita como dado sigiloso. Por exemplo a tabela inteira de Colaboradores seria caracterizada como sensível. Não aprece tão óbvio, mas uma tabela que guarda cópias de certidões de nascimentou ou de históricos médicos, mesmo não tendo colunas específicas, se caracteriza como dado sensível.
1.1. Se a tabela parece “inocente”, sem dados sensíveis, importante submeter ao próximo passo, varrendo coluna a coluna antes de afirmar que não tem nada sensível.
-
(nas demais tabelas) A cada coluna conferir se sua semântica bate com um dos itens LGPD.
Isso requer testar a propriedade sozinha (por exemplo sh:telephone já bate), como a propriedade da coluna no contexto de cada uma das classes da tabela. Por exemplo, o que faz a propriedade sh:name da coluna nome da tabela Colaboradores se transformar em wd:personName é o fato da coluna nome estar contida numa tabela classificada como sh:Person.
-
(nas demais colunas e tabelas) Refazer 1 e 2 considerando o conceito “mais geral” ou “mais específico”, caso seja nececessário um “pente fino” ou a atribuição semânica não tenha sido muito precisa.
-
Entre tabelas e colunas associadas a itens LGPD do grupo “Potencial informação sensível”, verificar se na base de dados há vínculo com itens LGPD do grupo “Caracterização da pessoa”. Se houver, é dado sensível.
-
Tratar exceções:
5.1. se no contexto da publicação do dado há risco do público deduzir.
Por exemplo havendo menos de 10 linhas em uma inocente “listagem de endereços dos funcionários do departamento X” pode-se alegar vínculo por todos conhecerem quem são as pessoas do departamento.
5.2. se houver comprovação de que é “pessoa pública”, com os mesmos dados (vinculados ou não) já publicados pelo governo por exemplo em Diário Oficial ou CNPJ.
5.3. … Outros tratamentos, tais como anonimização, caso seja constatado risco de vínculo.
Resumo
Os chamados “catálogos de dados” do banco de dados, quando baseados ou enriquecidos por tags semânticas padrão RDF, podem executar algorítmos similares aos descritos acima.
Tecnicamente as tags podem ainda ser auditadas por evidência estatística baseada em profile dos dados, revisão por terceiros, etc.