Boa @nitai, desenterrou do baú de 2013 um aspecto que não podemos nos esquecer (!) em meio à pressão por resultados e modismos.
… Eu ainda concordo com o artigo, mas não consegui escapar do Big Data, hoje trabalho com bancos Hive e HBase (do ecossistema Apache Hadoop) na VIVO, onde é comum ver tabelas ocupando petabytes. No passado já trabalhei com o padrão Frictionless Data citado no artigo: continua sendo um padrão recomendado pela comunidade de dados abertos, por garantir o nosso rumo às 5 estrelas dos dados abertos e à acessibilidade.
O small data citado corresponde hoje aos chamados “conjuntos de dados padronizados” (datasets), e quem institui essa padronização não é uma super-autoridade, sou eu ou você com ajuda da comunidade, inclusive fóruns de discussão como este. O pessoal do Brasil.io fez um bom trabalho reunindo datasets, expondo numa bonita interface e garantindo que eles “conversem entre si” tanto quanto possível (ainda pendente usarem FrictionlessData que dá trabalho).
Alguns dos datasets do Brasil.io também mostram que o conceito de small evolui com o tamanho dos nossos discos (o preço hoje do Terabyte de disco SSD é ~10% do preço de 2013)… Não são Big Data mas são datasets grandes.
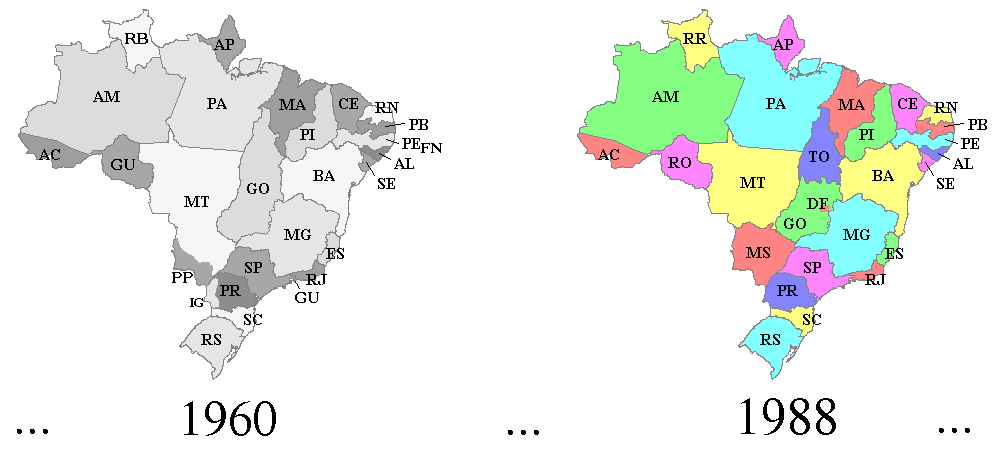
Vejamos um exemplo mais simples de small data enpacotado com padrão FrictionlessData, que qualquer leitor aqui do fórum está familiarizado: as siglas de Estado, abreviações de região, etc. e sua série histórica desde ~1960. Está em
GitHub - datasets-br/state-codes: Brazilian states 2-letter codes (ISO 3166-2:BR), official abbreviations throughout the country's history
O link para o visualizador de dapackage desse dataset mostra porque é importante interoperar através de padrões, e porque o custo de perder tempo descrevendo os dados (ou seja produzindo metadados) se justifica e muito!
PS: muitos dos antigos datasets são hoje gerados automaticamente pela Wikidata, por exemplo nesta consulta às regiões do Brasil
Hoje os padrões FrictionlessData podem ser compatibilizados com as boas práticas Big Data. Um Data Lake típico de Big Data tem milhares de tabelas, mas apenas 0.1% a 10% são Big (tabelas-fato), o restante são tabelas de dados auxiliares de relacionamentos (tabelas-referência), sem os quais não seria possível fazer conversões, gerar sumarizações estatísticas ou relatórios inteligíveis.
As equipes de Big Data do Brasil se descabelam para interpretar os dados, porque ninguém se dá ao trabalho de documentar através de metadados abertos (ainda é comum documentar com PDF!), assim como compor as dimensões de OLAP ou de modelos estrela, ou os simples SQL-Joins descritivos das sumarizações e relatórios, através de “small” datasets padronizados.
A comunidade de dados abertos tem muito a contribuir:
-
Cobrando padronização e interoperabilidade. O ativismo por padrões nunca termina, ainda hoje, principalmente nos portais do governo, é comum encontrar páginas que não cumprem com padrões mínimos, tais como usar UTF-8 no conteúdo das páginas (HTML) e nos dados CSV.
-
Ajudando a manter os datasets padronizados, como no
Brasil.io, Data Packaged Core Datasets,Datasets.OK.org.br, e muitos outros. -
Integrando os datasets padronizados com iniciativas maiores, como Wikidata.org.
Por ser um banco universal, semântico e estruturado, a Wikidata aos poucos absorverá (através por exemplo de geração automática SPARQL) os datasets, mas ainda demandará publicação em separado de versões estáveis, bem como monitoramento e controle da qualidade, etc. -
Convidando os gestores e equipes de governança Big Data das empresas e do governo a usarem e colaborarem com datasets padronizados.
À grande maioria dos “datasets públicos de interesse corporativo” também se aplicam, com mínimas adaptações, as boas práticas nos datasets - conforme W3C Brasil (DWBP). -
Dando exemplos brasileiros para a comunidade brasileira, e participando da padronização da marcação semântica em comunidades como o Schema.org… Já são mais de 2 bilhões de páginas com marcação semântica.
Só falta essa marcação semântica ser usada nas fontes primárias de conteúdo, como os Diários Oficiais: serão a principal fonte para a composição automática de datasets padronizados. Por exemplo de uma página HTML de Diário Oficial bem marcada (criada automaticamente como filha gêmea do PDF a partir do XML que já existe) pode-se extrair todos os metadados: quase 30 descritores transparentes embutidos no texto original de uma Lei.
@ppkrauss obrigado pelo texto. De fato o texto do Rufus nos faz lembrar de aspectos valiosos. Particularmente também não escapei do Big Data. Tenho estudado tecnologias relacionadas.
No fundo esses aspectos de small data reforçam a importância de padronização e interoperabilidade. A e-ping (que vc linkou no termo interoperabilidade  ) teve papel importante. Acredito que a demanda crescente por Ciência de Dados esteja criando uma pressão para uma retomada da e-ping.
) teve papel importante. Acredito que a demanda crescente por Ciência de Dados esteja criando uma pressão para uma retomada da e-ping.
Suas propostas de contribuições pela comunidade de dados abertos são muito boas.
Geralmente quando topo com críticas no estilo de forget big data, o texto costuma fazer uma crítica em torno de vieses, qualidade dos dados, e era isso que eu esperava. No entanto, fui surpreendido! Interessante esse conceito de small data, @nitai! ![]()
Em tempos onde muitos acham que basta um “N grande” e tudo está resolvido, acho o link abaixo uma boa leitura, e complemento ao forget big data, ou ao menos be careful with big data ![]()
Bem interessante também esse artigo, @mribeirodantas! Demonstra que, para a capacidade de realizar inferências em relação a uma população, é muito mais importante a aleatoriedade de uma amostra do que o seu tamanho.
Já o artigo do Rufus Pollock enfatiza que, para a atribuição de valor aos dados, muito mais importante que o seu tamanho é o seu potencial de reutilização em diferentes contextos, em diferentes organizações para resolver uma diversidade de problemas. E que, muitas vezes, os dados que são mais úteis não são big data.