Obrigado pela resposta @cuducos! Neste caso tenho que modificar o meu dockerfile, adicionando esse código: RUN apt install gcc ?
Olá pessoal, sou estudante de Engenharia de Dados e atualmente estou avaliando temas para meu TCC.
Pesquisando sobre dados abertos, encontrei a base do datasus, e os respectivos formatos .dbc e .dbf, além do trabalho da Daniela Petruzalek com a lib read.dbc citada nesse post.
Minha ideia inicial é criar uma lib de conversão direta de .dbc para .parquet (a escolha do parquet é por ser um formato binário e colunar que venho estudando, entendo que outros formatos podem ser mais interessante).
Não tenho ideia de como os usuários desses dados os usam em sua rotina. Alguém sabe me dizer se existe valor em uma lib que faz esse tipo de conversão direta para o formato parquet ?
Olá, @allan-silva, seja bem vindo ao fórum!
Sei que uma lib como essa lib já existe, no Python. A classe FTP_Downloader da biblioteca PySUS, mencionada na postagem original, faz o download dos dados do DataSUS e já os salva no formato Parquet.
Por exemplo,
In [1]: from pysus.online_data.sinasc import download
In [2]: download('SE',2015)
Out[2]: '/home/user/pysus/DNSE2015.parquet'
Se você for neste local, vai ver que o arquivo foi salvo no formato Parquet.
Ocorre que essa lib é específica para trabalhar com arquivos do DataSUS. Se você quiser converter arquivos .dbc “genéricos” para arquivos Parquet, você pode usar as mesmas libs que o PySUS usa: elas se chamam pyreaddbc e dbfread para ler os arquivos .dbc e .dbf, além do Pandas e do PyArrow, para escrever no formato Parquet. O código de conversão está aqui.
Já no R, que presumo que você esteja usando, já que mencionou o read.dbc, eu não sei se existe uma lib pronta para isso e nem como fazer, pois estou mais habituado é com o Python.
Oi @herrmann, obrigado pela resposta! A ideia do trabalho que pretendo desenvolver, é a conversão direta para o formato parquet, sem passar pelo pandas ou pelo formato arrow, também é uma lib para JVM.
Entendo que existe utilidade para o formato parquet, mas já existe uma lib estabelecida que faz a mesma coisa. Se eu for seguir com esse tema, posso adicionar o link depois, se for de interesse.
1 curtida
Saiu a versão 0.10.0 do PySUS! Para conhecer as novidades dessa versão, veja a página do release:
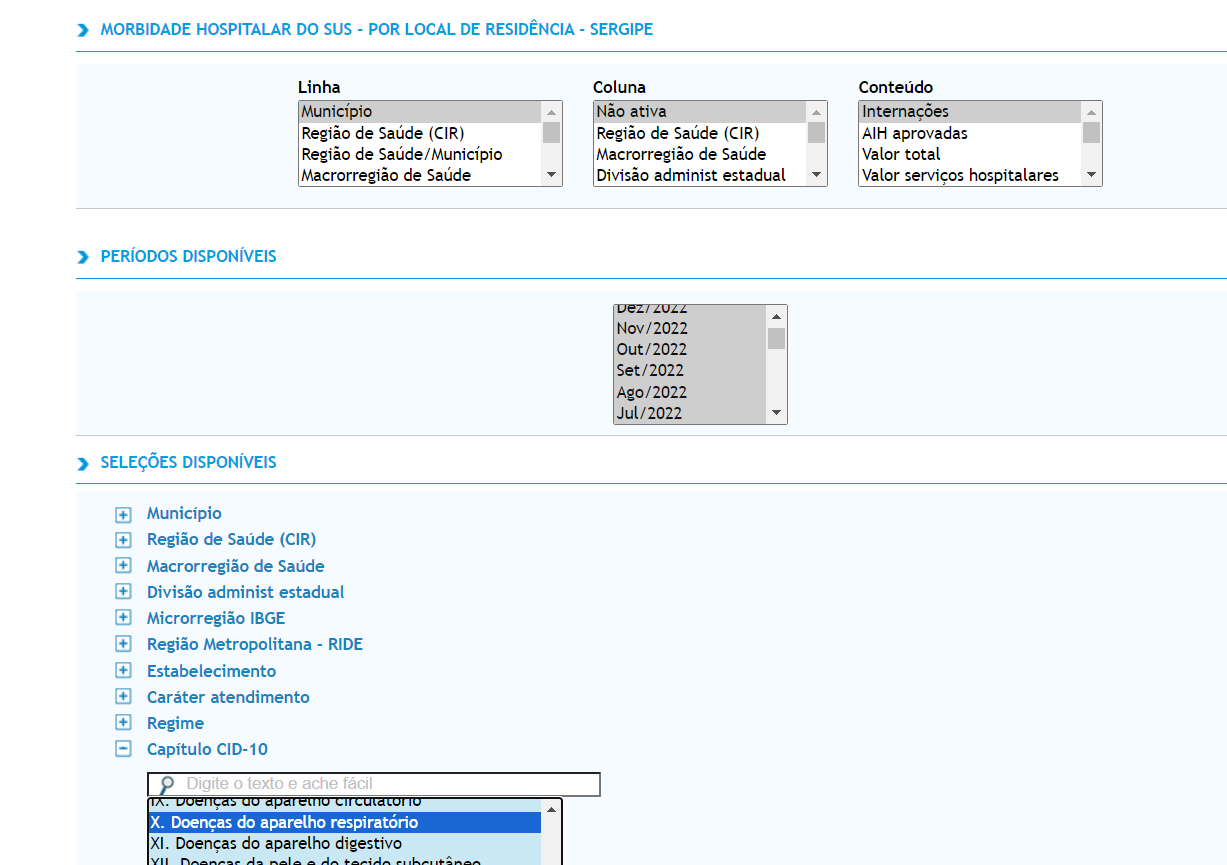
Olá! Estou refazendo um trabalho acadêmico sobre internações por doenças do aparelho respiratório em SE, vou retirar as informações daqui: TabNet Win32 3.3: Morbidade Hospitalar do SUS - por local de residência - Sergipe
da última vez que fiz isso foi tudo na munheca, copiando e colando… Tem como baixar usando esses códigos que mandaram? Porque precisa preencher alguns campos, por exemplo o print abaixo e ainda tem faixa etária e sexo. Alguém pode me dar uma luz?
Bem vinda, @cynthia.
Eu não entendo bem sobre o assunto desses dados, mas acredito que tenha jeito de baixar os dados, sim, usando códigos bem semelhantes aos que estão neste tópico.
O primeiro passo seria descobrir em qual sistema do DataSUS estariam os dados procurados. A lista dos sistemas é a seguinte:
- SINAN
- SINASC
- SIM
- SIH
- SIA
O que parece fazer mais sentido no contexto e que encontrei após fazer uma busca é o Sistema de Informações Hospitalares – SIH, o qual possui informações sobre morbidade.
Tentei o código seguinte no ipython e ele baixou alguns dados:
In [1]: from pysus.online_data.SIH import download
In [2]: from pysus.online_data import parquets_to_dataframe
In [3]: dfse = parquets_to_dataframe(download('SE',2022,12)) # para dezembro/2022
In [4]: dfse.head()
Out[4]:
UF_ZI ANO_CMPT MES_CMPT ESPEC ... TPDISEC6 TPDISEC7 TPDISEC8 TPDISEC9
0 280000 2022 12 01 ... 0 0 0 0
1 280000 2022 12 01 ... 0 0 0 0
2 280000 2022 12 01 ... 0 0 0 0
3 280000 2022 12 01 ... 0 0 0 0
4 280000 2022 12 01 ... 0 0 0 0
[5 rows x 113 columns]
O dataframe tem 113 colunas. Então é preciso ver na documentação dos dados quais dessas colunas serão úteis para a análise pretendida. O link está na postagem inicial deste tópico:
Após baixar o arquivo .zip, descompactar e procurar na pasta /Docs/ o documento chamado IT_SIHSUS_1603.pdf, encontrará a Tabela 1 com a descrição de cada coluna. No mínimo, as seguintes colunas devem ser úteis:
| SEQ | NOME DO CAMPO | TIPO E TAM | Descrição/Observações |
|---|---|---|---|
| 8 | CEP | char(8) | CEP do paciente. |
| 9 | MUNIC_RES | char(6) | Município de Residência do Paciente |
| 62 | CID_NOTIF | char(4) | CID de Notificação. |
Daí, para selecionar essas colunas no dataframe, faça
In [5]: dfse.loc[:,["CID_NOTIF", "CEP", "MUNIC_RES"]]
Out[5]:
CID_NOTIF CEP MUNIC_RES
0 49503102 280290
1 49007024 280030
2 49160000 280480
3 49065059 280030
4 49160000 280480
... ... ... ...
8640 49500000 280290
8641 49500000 280290
8642 49550000 280140
8643 49511899 280290
8644 48580000 292420
[8645 rows x 3 columns]
Na página que você enviou há um link intitulado “Notas Técnicas” onde é possível consultar a lista de códigos CID utilizados. A partir da pág. 10 tem a seguinte tabela com os códigos CID:
| Capítulo | Código | Descrição | Códigos da CID-10 |
|---|---|---|---|
| X | 165-179 | Doenças do aparelho respiratório | J00-J99 |
Então bastaria filtrar pelo código do CID desejado:
In [6]: dfse.loc[:,["CID_NOTIF", "CEP", "MUNIC_RES"]][dfse.CID_NOTIF == "J00"]
Out[6]:
Empty DataFrame
Columns: [CID_NOTIF, CEP, MUNIC_RES]
Index: []
o que retorna vazio pois não existe esse valor “J00” na coluna “CID_NOTIF”. De fato, a maioria dos valores para esse mês (dezembro/2022) está não preenchido para essa coluna, e apenas 214 linhas possuem o valor “Z302”.
In [7]: dfse.CID_NOTIF.value_counts()
Out[7]:
8431
Z302 214
Name: CID_NOTIF, dtype: Int64
Talvez outra coluna seja mais útil para a análise. Mas esse é um ponto de partida, acredito que você consiga seguir a partir daí.
Olá a todos. Prazer em poder participar do Fórum.
Aproveitando a oportunidade. Alguém saberia dizer onde estão os dados de Febre Amarela mais recentes? Apesar de ser notificável, não encontram-se no SINAN (procurei no FTP, site, PySUS e etc).
No site do MS achamos alguns fragmentos de informação, especialmente entre o período de 2001 a 2006. Contudo, não consigo achar nada mais recente. Estou procurando no lugar errado? Alguém saberia onde achar esses dados mais recentes?
Obrigado!
Bem vindo, @brunoMT!
Realmente. Segundo a documentação do PySUS sobre o SINAN, a febre amarela estaria presente nos dados, sim.
In[1]: from pysus.online_data import SINAN
In [2]: SINAN.list_diseases()
Out[2]:
['Animais Peçonhentos',
'Botulismo',
'Cancer',
'Chagas',
'Chikungunya',
'Colera',
'Coqueluche',
'Contact Communicable Disease',
'Acidentes de Trabalho',
'Dengue',
'Difteria',
'Esquistossomose',
'Febre Amarela',
'Febre Maculosa',
'Febre Tifoide',
'Hanseniase',
'Hantavirose',
'Hepatites Virais',
'Intoxicação Exógena',
'Leishmaniose Visceral',
'Leptospirose',
'Leishmaniose Tegumentar',
'Malaria',
'Meningite',
'Peste',
'Poliomielite',
'Raiva Humana',
'Sífilis Adquirida',
'Sífilis Congênita',
'Sífilis em Gestante',
'Tétano Acidental',
'Tétano Neonatal',
'Tuberculose',
'Violência Domestica',
'Zika']
Porém, ao pesquisar os anos disponíveis, vem uma lista vazia:
In [3]: SINAN.get_available_years("Febre Amarela")
Out[3]: []
Isso não acontece com algumas outras doenças, por exemplo, a dengue:
In [4]: SINAN.get_available_years("Dengue")
Out[4]:
['2000',
'2001',
'2002',
'2003',
'2004',
'2005',
'2006',
'2007',
'2008',
'2009',
'2010',
'2011',
'2012',
'2013',
'2014',
'2015',
'2016',
'2017',
'2018',
'2019',
'2020',
'2021',
'2022',
'2023']
Ao olhar na página de download de dados do DataSUS (link na postagem original do tópico), de fato está faltando a febre amarela no SINAN:
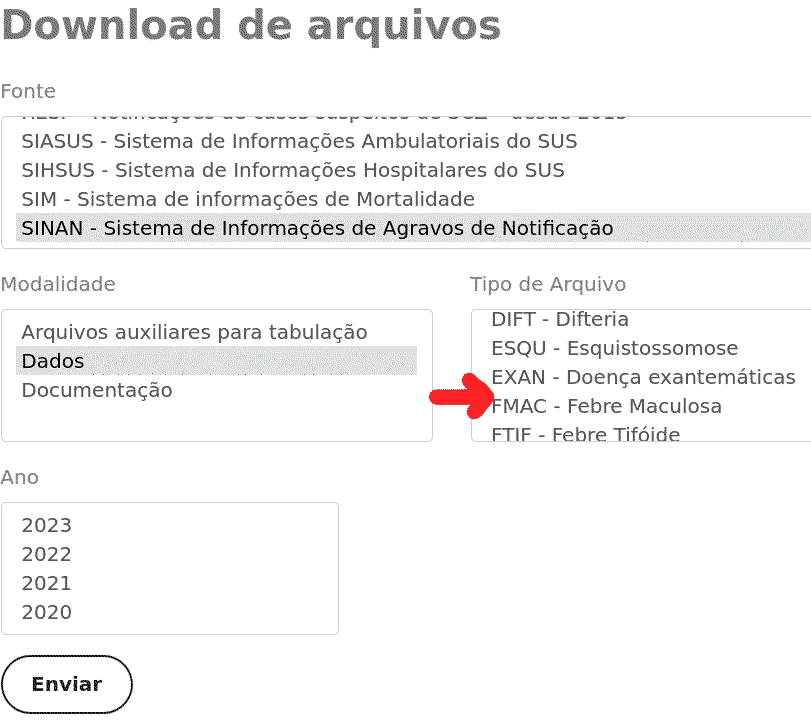
Talvez valha a pena questionar o DataSUS a falta destes dados pelo “fale conosco” ou fazer um pedido via Lei de Acesso à Informação.
Olá, quando listamos a estrutura de dados públicos pelo FTP, aparentemente existem mais dados que a UI do site disponibiliza. Alguém sabe se existe alguma documentação que descreve cada uma dessas pastas ?
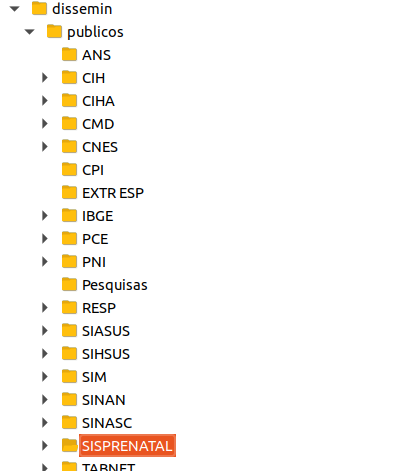
De fato aparentemente alguns arquivos não possuem documentação, até onde sei. Algumas pastas também estão vazias. Em outras, é possível encontrar uma subpasta com o nome Doc contendo um documento PDF – aparentemente esse documento é a documentação daquela pasta.
1 curtida
Olá a todos,
Recentemente, me deparei com um repositório que trata sobre a ferramenta SABEIS e procurei mais sobre o tema, principalmente sobre ETL. Pelo que entendi, essa ferramenta está muito relacionada com o tópico aqui levantado. Aliás, existe até essa página interativa. Contudo, os dados estão desatualizados. Gostaria de saber como posso executar essa aplicação no Colab e atualizar as tabelas .csv que foram utilizadas. Além disso, se seria possível filtrar a visualização por UFs.
Obrigado!
Olá pessoal, estou utilizando o PySUS para baixar dados do SINAN, e percebi que consigo baixar os dados de 2007 a 2024 que estão disponíveis no FTP já disponibilizado neste tópico.
No entanto existem dados de 2000 a 2006 que estão disponíveis via TabNet nest link:
https://datasus.saude.gov.br/acesso-a-informacao/doencas-e-agravos-de-notificacao-2001-a-2006-sinan/
Mas não consegui encontrar o arquivo *.dbc referente aos dados de 2001 a 2006, seja pela PySUS ou pelo FTP.
Por acaso alguém conseguiu acessar o *.dbc referente ao período de 2001 a 2006?
E porque será que os dados de 2001 a 2006 estão separados dos dados de 2007 em diante?
Tem razão. Vi que nesse link é possível também baixar os arquivos no formato csv. A URL desses arquivos csv pode ser compartilhada e o download funciona. Então parece que tem uma lógica nisso aí. Parece ser possível estudar essa lógica e acrescentar suporte a esse período em ferramentas como o PySUS.
Talvez valha a pena abrir uma issue lá no Github do PySUS sugerindo isso. Para anotar essa necessidade e quando alguém tiver disponibilidade poder estudar essa fonte de dados e implementá-la.
Sobre a razão desse período estar em uma fonte de dados separada, eu não faço ideia. Às vezes isso acontece quando muda a metodologia de coleta de dados, o que inviabiliza realizar análises considerando uma linha de tempo contínua.
Olá pessoal, para quem está trabalhando com Java, ou Scala, publiquei recentemente uma biblioteca para conversão de arquivos DBC/DBF em formato Parquet, compatível com Spark/Hadoop, disponível apenas para Linux no momento.
Os binários podem ser encontrados no maven.
As instruções de uso estão no repositório do projeto:
Recursos:
- Descompressão de arquivos DBC.
- Descompressão uma lista de arquivos DBC presentes em um diretório.
- Conversão de arquivos DBC ou DBF para Parquet.
- Conversão de uma lista de arquivos DBC ou DBF para um único arquivo parquet, possibilitando combinar os arquivos disseminados por competência (Mês/Ano).
1 curtida
Não temos nenhuma solução em python para lidar com arquivos dbc até o momento?
Olá, @Dan, bem vinda(o) ao fórum!
Existe uma solução em python, sim, para lidar com arquivos dbc. É para ler arquivos do DataSUS ou arquivos dbc “genéricos”? De qualquer forma, sugiro que leia a resposta acima, da qual cito aqui um trecho:
Para ir para a o texto completo, basta clicar na referência.
Boa tarde.
Eu coloquei em um repositório (GitHub - ipencnensp/converteDBC2Parquet: Conversão de arquivos DBC do DATASUS para Parquet utilizando R) alguns scripts que utilizo para converter os arquivos DBC para Parquet utilizando R.
No meu caso, eu faço um mirror do FTP do DATASUS, utilizando o wget e escolhendo os dados específicos, por exemplo, APACS de Pronto-Atendimento (“PA”) do SIASUS, ou os arquivos do SIHSUS.
Com estes arquivos organizados em pastas específicas na minha máquina, rodo os scripts de conversão.
Os arquivos Parquet resultantes serão organizados por UF e ANO, em caminhos HIVE (ESTADO=UF/ANO=YYYY).
Utilizando o wget para fazer mirror, os arquivos baixados conterão o mesmo timestamp dos originais; assim, quando o script de conversão for chamado, ele só vai criar (ou recriar) os arquivos Parquet para os ANOS que tiveram algum arquivos DBC modificado pelo DATASUS, ou seja, com data de modificação mais recente do que o Parquet daquele ano. Os arquivos Parquet são criados com o mesmo timestamp que os DBC originais para permitir essa verificação.
Esses scripts foram desenvolvidos e testados somente no Linux.
Abraços.
1 curtida