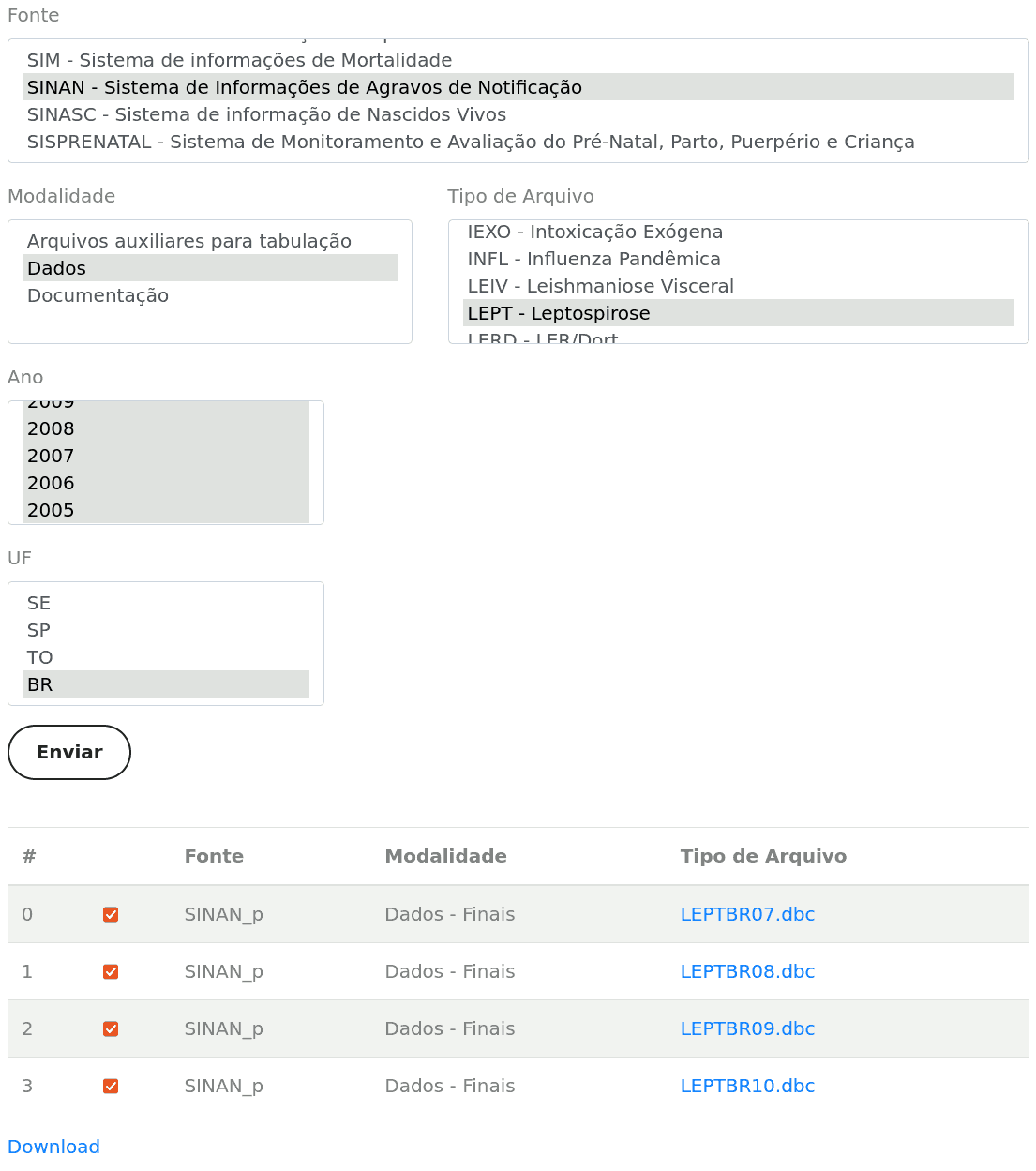
@anm.nardoni, esse site cujo link você compartilhou ajuda a obter as variáveis que precisam ser preenchidas: sistema, modalidade, tipo_arquivo, etc. Vá preenchendo o formulário e ao final o site exibe um link para download em FTP. Esse link vem na forma
Então, no seu caso, acho que o sistema é o SINAN – Sistema de Agravos de Notificação. Selecione Leptospirose, maque os anos desejados, no campo UF escolha “BR” e clique em “enviar”.
Pelo visto, parece que os anos disponíveis para esse agravo são de 2007 a 2020.
Daí seria apenas iterar a função para pegar os anos desejados e concatenar os dataframes. Só não consigo ajudar com o código em R pois disso eu não entendo quase nada.
Boa tarde pessoal.
Estou fazendo um trabalho com dados públicos do Inca e
gostaria de saber se é possível realizar uma análise preditiva com esses dados.
Alguém já teve contato e poderia me ajudar?
Os dados são qualitativos e as informações das variáveis transformadas em números 1, 2, 3, 4, etc.
Exemlpo: 1 - fumante, 2 - nunca fumou, 3 - ex fumante, 4 - sem informação, …
Gostaria de analisar as variáveis: álcool, tabaco, histórico familiar, instrução, raça/cor, idade.
Se alguém tiver alguma informação e puder ajudar agradeço!
Existem diversas formas de se fazerem análises preditivas. Quando os dados estão representados como uma série temporal, dependendo do seu comportamento, podem-se usar, por exemplo, desde técnicas estatísticas como regressão linear até técnicas de machine learning como as redes neurais recorrentes (RNN).
Porém, pelo que você descreve dos dados me parece mais com um problema de classificação. Existem muitas técnicas de machine learning para classificação. Se você precisa que o seu modelo seja explicável, terá que usar técnicas que lhe deem essa possibilidade, por exemplo um classificador random forest. Já se não houver a necessidade de explicar as decisões do modelo, podem ser usados também outros modelos baseados em redes neurais.
Segue uma referência que, embora esteja sem atualização há algum tempo, ainda tem muita coisa interessante para consultar e aprender:
Olá pessoal.
Passei boa parte do fds lembro o fórum.
Parabéns a todos pelas contribuições.
Infelizmente estou com muita dificuldade para instalar as ferramentas sugeridas.
Minha preferencia era o python, mas dá erro ao rodar o docker proposto nos links.
Em R tentei instalar o microdatasus, não dá certo sequer os pacotes de devtools…
Nem o dbc2csv rodou.
Até instalou super bem e o docker foi legal, mas qdo digito a linha de comando de conversão sempre dá um erro referente ao caminho do diretório criado com os arquivos dbc.
Agradeço muito a ajuda de quem puder me dar uma orientação, especialmente se conseguirmos fazer em python.
Não sei de qual docker você está falando. Pesquisei por “docker” neste tópico e a única referência que encontrei foi esta sua própria mensagem.
Acabei de testar o exemplo acima para baixar os dados do SINASC usando o PySUS em Python funcionou. Só precisei antes instalar o pacote fazendo
pip install pysus
Editado: agora entendi de que docker você está falando, é da ferramenta dbc2csv. Mas não é necessário converter para CSV se tudo o que você quer é usar os dados em Python. Basta usar o pacote PySUS citado na seção sobre Python da postagem inicial: ele já te dá um dataframe em Pandas que pode ser utilizado para análises, visualizações, etc. Dá até para gravar em CSV, se você realmente precisar, usando o método df.to_csv() do Pandas.
Tente pesquisar em um site de buscas pela mensagem de erro que estiver aparecendo ao instalar o pacote. Eu não tenho como te ajudar com uma instalação no Windows pois fazem quase 20 anos que não utilizo nenhum sistema Windows.
Editado: se você está tendo problemas para instalar pacotes Python no Windows, uma outra ferramenta que poder facilitar a instalação é o Anaconda. Além disso, alguns colegas que usam Windows costumam usar o Python pelo WSL.
Estou fazendo um projeto na empresa que a minha função é apresentar uma api que eu possa extrair dados do DataSus/tabnet, podem me ajudar? e tambem como posso filtrar e extrair os dados somente de produção do SUS de municipios de Alagoas?
Você poderia usar um dos métodos descritos na primeira postagem desse tópico para baixar os dados e carregá-los em um banco de dados (por exemplo, PostgreSQL).
Para filtrar, veja se os arquivos dos quais você precisa já estão divididos por estado/região, para economizar tráfego de rede no download dos dados. Você pode ver nas colunas do banco, na tabela que lhe interessa, se há uma com a definição da UF, e então filtrar por cláusula WHERE na query SQL.
Por fim, usar algum framework de APIs em software livre, como o FastAPI ou PostgREST para criar uma API.
Bom dia! É possivel eu somente extrair dados especificos do SIA? Queria extrair os dados De radioterapia Mas somente de Hospitais do Nordeste, capital, e no periodo de 2012-2022.
Bruno, o erro “not enough values to unpack” quer dizer que a função download não está retornando nenhum valor e você está tentando atribui-lo a duas variáveis: bi e ps.
Acredito que é possível que os dados não estejam mais disponíveis. O próprio link para download dos dados do DataSUS foi alterado e, ao pesquisar os arquivos de bancos de dados disponíveis na página do DataSUS, não aparece a opção “SIA”. Tem “SIASUS” e dentro dele tem a opção “PA - Produção ambulatorial”. Mas os arquivos “BI” e “PS” não estão disponíveis na página do DataSUS, ou pelo menos não consegui encontrá-los. Acredito que a falta desses arquivos na origem seja o que origina o problema.
Consegui ler os arquivos. O problema é que o ambiente Python que eu estava usando tinha o Python 3.8.10 e a versão atual do PySUS requer no mínimo o Python 3.9. Depois de atualizar o Python para 3.9, funcionou certinho.
No meu caso, eu estava usando o Ubuntu 20.04 e precisei fazer:
Se entendi corretamente, você quer obter o número do SINASC para casos individuais de nascimento, é isso mesmo? Se for, não encontrará essa informação nessa base, pois ela é de acesso público (dados abertos) e por isso precisa ser anonimizada, de forma que não seja possível identificar individualmente as pessoas e seja preservada a intimidade e a vida privada, direito fundamental previsto no art. 5º inciso X, da Constituição Federal de 1988 e art. 31 da Lei de Acesso à Informação.
Para quem é profissional de saúde e tem necessidade de acesso individualizado aos dados do paciente que precisa atender, existem os meios próprios para ter acesso autorizado. A Lei n.º 13.787/2018, por exemplo, define as regras do prontuário eletrônico do paciente. Porém isso escapa do conceito de dados abertos, que é a temática deste fórum.
Em 2019 fiz download das informações de 2016, 2017 e 2018 e nos arquivos existia o número DN em ambas tabelas SIM e SINASC. Isto foi interessante pois pude analizar a questão de recen-nascidos prematuros que chegaram a óbito depois de 1 ano de nascido. Agora Infelizmente não irei conseguir prosseguir na minha pesquisa. Os dados do SIM e SINASC juntos seriam bastante úteis mas separados limitam bastante os estudos.
@mfernandes75, o que escrevi acima se aplica a informações pessoais em geral, e por que elas não são disponibilizadas ao público.
Quanto ao número DN, no caso particular, à primeira vista ele me pareceu ser uma informação capaz de identificar o indivíduo. Entretanto, eu não tenho conhecimento especializado para afirmar se ele é ou não uma informação pessoal ou se ele foi ou não retirado dos dados ou por quê. Sugiro que você leia a documentação e os dicionários de dados dessas tabelas atuais procurando informações sobre esse campo e, permanecendo a dúvida, entre em contato com o DataSUS para obter maiores esclarecimentos.
Boa tarde, pessoal! Sou novo por aqui e não sei se estou postando no local correto. Acontece que estou desenvolvendo um ETL e estou utilizando o pysus para fazer a extração de alguns dados. Nesse projeto estou utilizando o astro cli como ambiente dev. Ao adicionar o pysus==0.9.3 no requirements.txt, estou obtendo o seguinte erro:
│ exit code: 1
╰─> [85 lines of output]
/tmp/pip-install-n9ztk9qy/pyreaddbc_0999fa703b9c4245a1773772adfefeda/pyreaddbc/_readdbc.so
generating ./pyreaddbc/_readdbc.c
(already up-to-date)
the current directory is ‘/tmp/pip-install-n9ztk9qy/pyreaddbc_0999fa703b9c4245a1773772adfefeda’
Traceback (most recent call last):
File “/tmp/pip-build-env-kgu3e5ab/overlay/lib/python3.10/site-packages/setuptools/_distutils/spawn.py”, line 57, in spawn
proc = subprocess.Popen(cmd, env=env)
File “/usr/local/lib/python3.10/subprocess.py”, line 971, in init
self._execute_child(args, executable, preexec_fn, close_fds,
File “/usr/local/lib/python3.10/subprocess.py”, line 1863, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
FileNotFoundError: [Errno 2] No such file or directory: ‘gcc’
```
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/tmp/pip-build-env-kgu3e5ab/overlay/lib/python3.10/site-packages/setuptools/_distutils/unixccompiler.py", line 185, in _compile
self.spawn(compiler_so + cc_args + [src, '-o', obj] + extra_postargs)
File "/tmp/pip-build-env-kgu3e5ab/overlay/lib/python3.10/site-packages/setuptools/_distutils/ccompiler.py", line 1041, in spawn
spawn(cmd, dry_run=self.dry_run, **kwargs)
File "/tmp/pip-build-env-kgu3e5ab/overlay/lib/python3.10/site-packages/setuptools/_distutils/spawn.py", line 63, in spawn
raise DistutilsExecError(
distutils.errors.DistutilsExecError: command 'gcc' failed: No such file or directory
ERROR: Could not build wheels for pyreadrbc, which is required to install pyproject.toml-based projects
Alguém sabe alguma solução?
Lendo a mensagem de erro No such file or directory: ‘gcc’ me parece que uma dependência do pysus chamada pyreadrbc precisa de um compilador C chamado gcc e isso não tem no teu sistema.
Se você usar algum Debian-based, apt install gcc ou apt install bulid-essential (como o pysus usa em seu container) deve resolver ; )